
About Me
I am currently a Research Resident at FAR AI, exploring critical challenges in AI safety and mechanistic interpretability, with a particular interest in uncovering how large language models (LLMs) persuade and influence people. Concurrently, I am pursuing my PhD as an NSERC CGS-D scholarship recipient at York University, where I am part of the CVIL Lab under the supervision of Dr. Kosta Derpanis. My doctoral research emphasizes mechanistic interpretability in multi-modal video understanding systems.
My journey in AI research includes impactful industry experiences, such as internships at Ubisoft La Forge, where I worked on generative modeling for character animations, and at Toyota Research Institute, contributing to interpretability research for video transformers within the machine learning team. Additionally, I hold a position as a faculty affiliate researcher at the Vector Institute and previously served as Lead Scientist in Residence at NextAI (2020–2022).
My academic path began with a Bachelor of Applied Science (B.A.Sc) in Applied Mathematics and Engineering, specialized in Mechanical Engineering from Queen’s University in Kingston, Ontario. Following graduation, I gained practical engineering experience at Morrison Hershfield, collaborating in multidisciplinary teams to design buildings, laboratories, and residential projects.
I then earned my Master’s degree at the Ryerson Vision Lab in August 2020, co-supervised by Dr. Neil Bruce and Dr. Kosta Derpanis. My thesis focused on evaluating the effectiveness of various modalities in recognizing human actions.
Outside of research, I am a chronic hobbyist. I enjoy maintaining an active lifestyle focused on health and fitness through weightlifting and calisthenics, engaging competitively in Super Smash Bros. Melee, cooking, skateboarding, rock climbing, birdwatching, close-up magic, and immersing myself in the progressive house and techno music scene.
Project Highlights


Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models
Unsupervised discovery of concepts and their interlayer connections.
Paper, project page, demo.

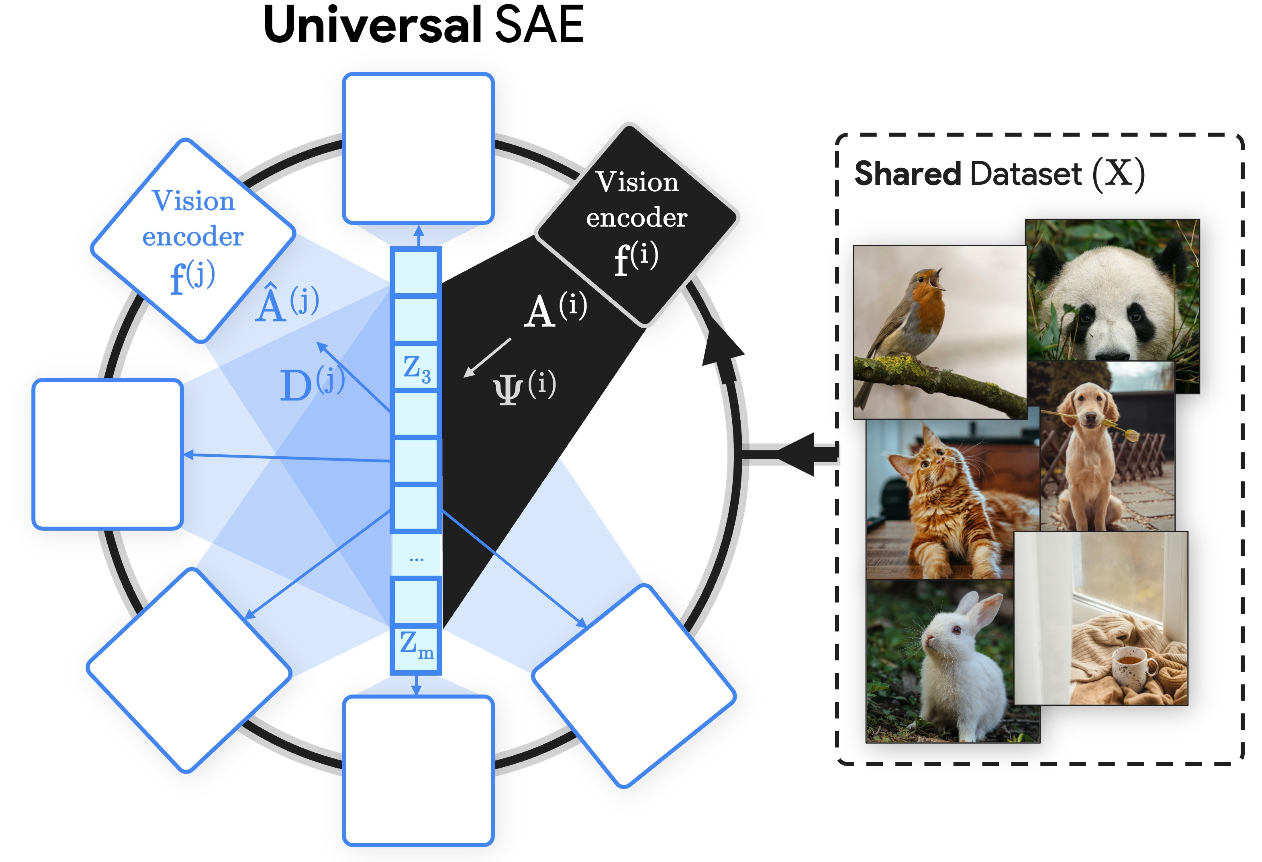
Understanding Video Transformers via Universal Concept Discovery
We discover universal spatiotemporal concepts in video transformers.
Paper, project page.
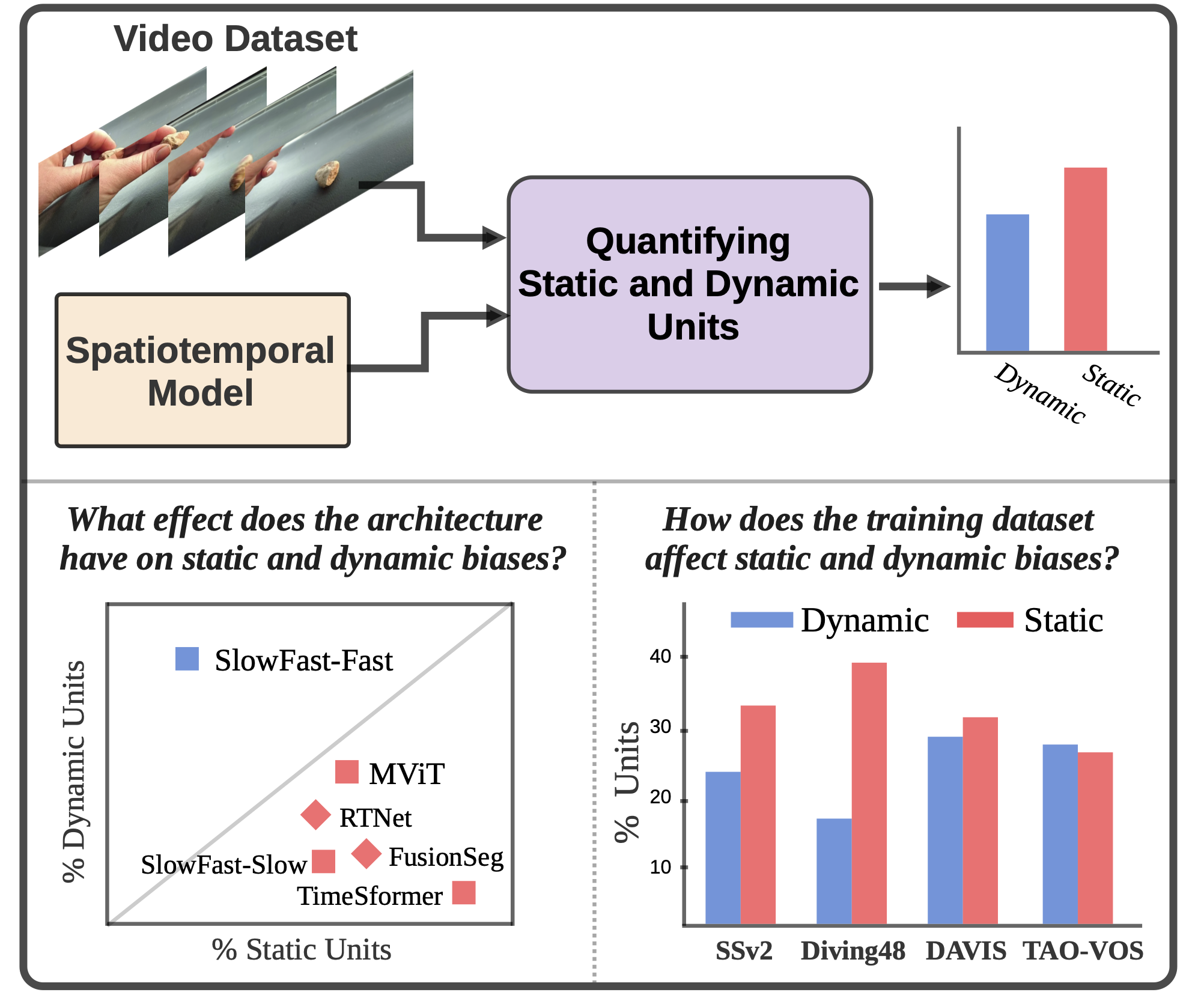
A Deeper Dive Into What Deep Spatiotemporal Networks Encode
We develop a new metric for quantifying static and dynamic information in deep spatiotemporal models.
Paper, project page.


Shape or Texture: Understanding Discriminative Features in CNNs
We develop a new metric for shape and texture information encoded in CNNs.
Paper, project page.

Feature Binding with Category-Dependent MixUp for Semantic Segmentation and Adversarial Robustness
Source separation augmentation improves semantic segmentation and robustness.
Paper.
News
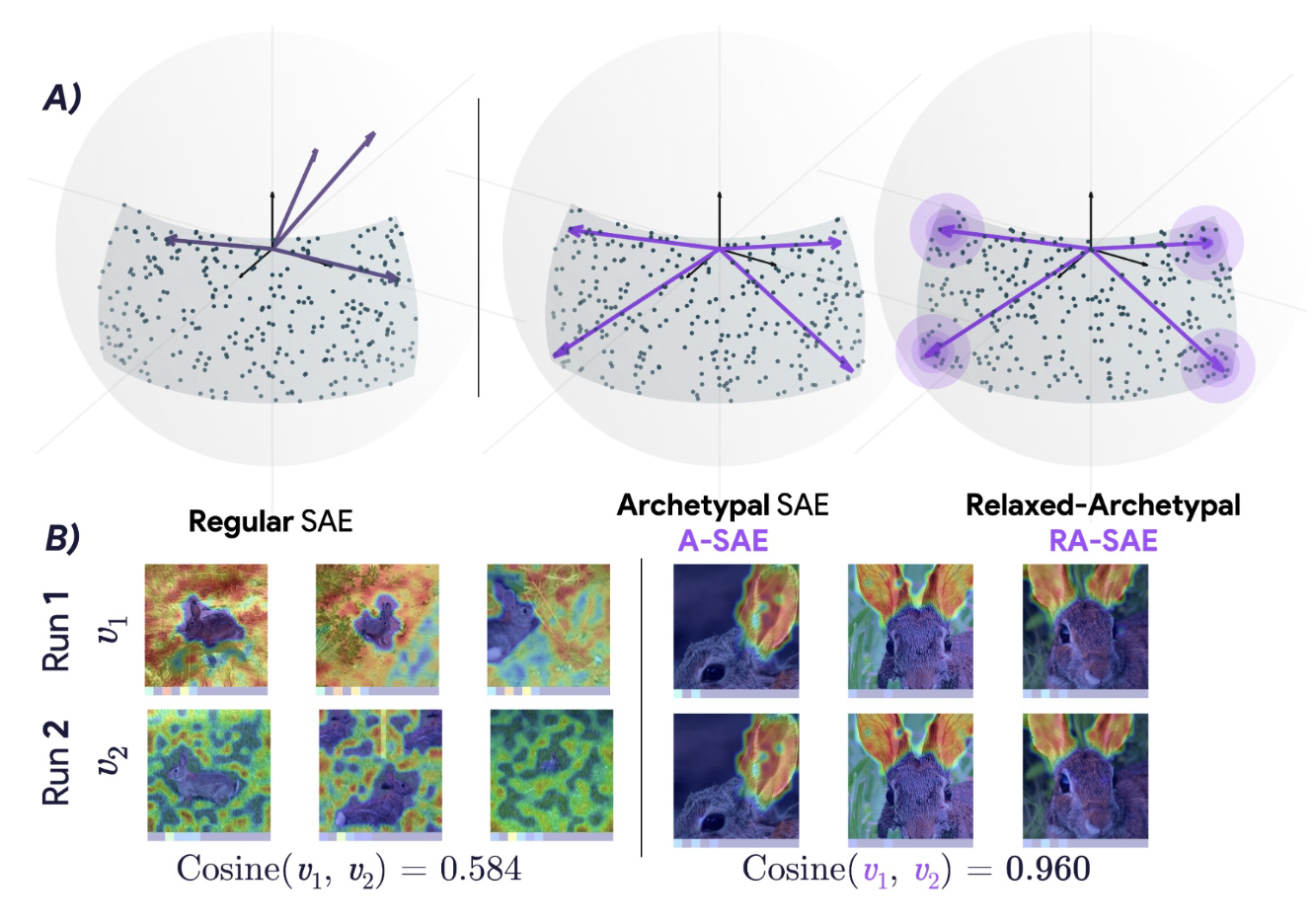
- Two papers accepted to ICML 2025 improving intepretability methods with SAEs! Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment and Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models!
- I joined FAR.AI as a Research Resident working on understanding LLM persuasive capabilities!
- Gave an invited talk at David Bau’s Lab at Northeastern University!
- Gave an invited talk at Thomas Serre’s Lab at Brown University!
- Paper accepted to TPAMI! Quantifying and Learning Static vs. Dynamic Information in Deep Spatiotemporal Networks. Paper
- TWO papers accepted as Highlights at CVPR 2024!
- CVPR 2024 paper accepted as a Highlight, a result of my Internship at Toyota Research Institute - Understanding Video Transformers via Universal Concept Discovery. Paper and project page! We will also be presenting this work as a poster at the Causal and Object-Centric Representations for Robotics Workshop
- CVPR 2024 paper accepted as a Highlight - Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models. Paper and project page. We will also be presenting this work as a poster at the CVPR Explainable AI for Computer Vision Workshop
- CAIC 2024 long paper accepted - Multi-modal News Understanding with Professionally Labelled Videos (ReutersViLNews) . Paper.
- Paper accepted to the International Journal of Computer Vision (IJCV) - Position, Padding and Predictions: A Deeper Look at Position Information in CNNs . Paper.
- I have been awarded the NSERC CGS-D Scholarship with a total value of $105,000! (Accepted)
- I have accepted an offer to do a research internship at Toyota Research Institute for the Summer of 2023 at the Palo Alto HQ office!
- I gave a talk at Vector’s Endless Summer School program on Current Trends in Computer Vision and a CVPR 2022 Recap
- Paper accepted to the International Journal of Computer Vision (IJCV) - SegMix: Co-occurrence Driven Mixup for Semantic Segmentation and Adversarial Robustness. Paper.
- I presented a spolight presentation at the Explainable AI for Computer Vision Workshop at CVPR 2022. You can watch the recorded talk here.
- Paper Accpted to CVPR 2022 - A Deeper Dive Into What Deep Spatiotemporal Networks Encode: Quantifying Static vs. Dynamic Information. Paper and Project Page.
- Paper Accepted to ICCV 2021 - Global Pooling, More than Meets the Eye: Position Information is Encoded Channel-Wise in CNNs. Paper.
- Paper Accepted to BMVC 2021 - Simpler Does It: Generating Semantic Labels with Objectness Guidance. Paper.
- Paper Accepted to ICLR 2021 - Shape or Texture: Understanding Discriminative Features in CNNs. Paper.
- Paper Accepted as an Oral to BMVC 2020 - Feature Binding with Category-Dependant MixUp for Semantic Segmentation and Adversarial Robustness. Paper.